
Introduction
MLOps combines machine learning lifecycle management with the infrastructure code and processes of DevOps. It bridges the gap between data science and operations by automating the ML lifecycle, enabling continuous integration, deployment, and monitoring leading to iterative improvements of ML Models. This helps in standardizing and streamlining the machine learning lifecycle, ensuring reproducibility and scalability of ML workflows. Moreover, this accelerates the process of taking ML models from development to production and reducing time-to-market for AI drive solutions. MLOps ensures model reliability, governance, and compliance vital in regulated industries and mission-critical applications.
Challenges
Without MLOps, organizations face various challenges impacting the productivity and outcome of these projects. One significant issue is the extensive time spent on manual processes in data preprocessing to model deployment and monitoring. These are not only time consuming but also prone to errors. Moreover, without automated tools, Scaling and managing data pipelines becomes inefficient as the complexity of operations increases with increasing volume and variety of data. Therefore embracing MLOps is a critical step towards agility and maintaining a competitive edge in the market.
Our Proposed Solution
We are going to focus on Azure ML Service and MLFlow and how our Automated Solution built on it could help to overcome the above challenges in Data Science Projects. Our Goal of this Project is to automate the production of an MLOps Pipeline which will enable generic reusability for various ML Use cases. Using MLFlow with AzureML allows us to leverage its capabilities within the Azure ecosystem. This helps us to track Azureml experiments and log various metrics like accuracy, precision, etc which provides a transparent view of our models‘ performance and helps us to compare between different applications with ease. Our Proposed Solution consists of two parts.
Infrastructure
In the first part, we use Terraform to create the required infrastructure for deploying ML use cases in Azure.
Azure ML Pipeline
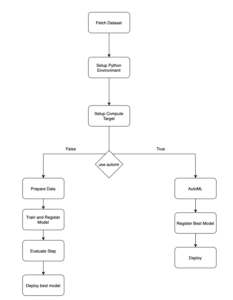
This part consists of the MLOps pipeline using Python SDK. We start with the configuration of the AML Workspace to interact with the Azure Services. Then we do the environment setup by defining a conda specification file, enabling consistent package installations across different compute targets. The next step is to configure the Compute Target using GPU-based instances for executing ML workloads. The Compute cluster scales dynamically based on the workload demands. Once the setup is completed, We start with fetching datasets for ML Training, AzureML simplifies data management through Datastores, We register an Azure Blob Container as a Datastore, facilitating easy access to datasets stored in Blob Storage.
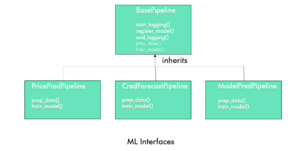
The core of this solution lies in these 4 subsequent steps from Data Preprocessing, Training, Evaluation, and Deployment as Inference endpoint. We adopted an object-oriented approach by encapsulating ML functionalities into reusable classes and methods. This helped us to achieve modularity, reusability, and extensibility. The methods defined in the base class could be redefined and overridden by the Child Class as per the requirements. To demonstrate this capability, we have abstracted the reusable components of this pipeline inside mlops/src/ml_pipeline_abstractions. It contains a base pipeline and a child pipeline class. The methods defined in the BasePipeline Class can be overridden by the Child Pipeline definitions.
Data Preprocessing
The Preprocessing step retrieves the AzureML Datastore which is connected to the Blob Storage. After retrieval, it loads the dataset as an AzureML Tabular Dataset. Subsequently, we filter out the headers and indexes from the data before deploying it in the training function. This step could be further customized by allowing clients to create their version of the `prepare_data` method in the Child Class definition
Model Training
In the Model Training step, we offer a combination of custom and predefined training functions encapsulated within modular classes. This allows flexibility to clients who prefer to utilize their proprietary algorithms. Clients can seamlessly integrate their unique training functions by incorporating them into the utils package and toggling the option to employ a custom training function. Simultaneously, our system allows for the selection of a primary metric to guide model performance evaluations. Clients can choose from a comprehensive suite of metrics, including accuracy, precision, recall, f1 score, ROC AUC, and the confusion matrix. The chosen primary metric is logged into the Azure Machine Learning (AML) Workspace, ensuring a transparent and comparative assessment of model performance.
Model Evaluation
In the subsequent evaluation phase, our focus shifts to the comparison of this primary metric across all trained models. Through this comparison, we identify the model with the best performance within the model registry. This model is then added with a „production“ tag, signifying its readiness for deployment.
Model Deployment
The final phase is the deployment phase where the best model is chosen by filtering on the ‘production’ tag. The model is deployed as a real-time endpoint to provide a scalable and accessible web service for machine learning inference.
Workflow of ML Pipeline
Auto ML
We have also provided integration with Azure AutoML capabilities. This enables our client to train their datasets using a range of models. This can be achieved by setting up the Automl flag to true. After training, this process culminates in a detailed comparison between the trained models, highlighting their performance metrics. We can define our primary metric while configuring the AutoML function, Accordingly, the pipeline selects the best-performing model. In the next steps, we register this model to the registry and deploy it as an inference end-point.
By incorporating AutoML, we empower our clients to harness the power of machine learning without the need for extensive expertise and help them leverage their datasets effectively.
Integration with Azure DevOps for CI/CD
The Azure DevOps CI/CD pipeline automates the MLOps process by orchestrating a sequence of tasks to ensure the smooth deployment of ML Models. A set of predefined variables is set to configure the environment which is utilized for the subsequent tasks. At first, authentication is set using a service connection that gives access to our Azure subscription and its resources. The next step is to deploy Terraform to provision the necessary infrastructure as described above. Subsequently Python environment is set and the MLOps pipeline Python script is executed. This completes the end-to-end MLOps workflow deployment. We have integrated AzureDevOps with Github, This ensures that our Azure pipeline is triggered every time there is a commit in the master branch of the Github repository.
Conclusion
It can be concluded that the above MLOps project stands as an accelerator streamlining the transition from experimental machine learning to robust production systems. The modularity in selecting metrics, training functions, Automl, etc ensures a very flexible and agile solution that will help our clients accelerate their AI-driven products and services development. It will provide an overall competitive advantage in the market driven by high-performing, reliable, and scalable machine learning solutions.

