
There are many business, mathematical, computer science problems that can be solved with the general methods of discrete mathematics (discretely structured mathematical systems). For example, finding the largest number among a set of integers or putting them all in increasing order or finding the shortest part between two vertices of a graph model. To complete these types of tasks, a certain method is needed that will reach the solution in a reasonable time. Ideally, a method with a precise description of steps that lead to an answer. We call such a procedure an algorithm. Here is a more concrete definition.
Definition: An algorithm is a (finite) sequence of precise instructions (steps) to perform a computation (in order to solve a problem).
Historical Note: The name algorithm comes from the name of the 9th century mathematician “al-Khowarizmi”. The word “algorism” was being used initially for performing arithmetic operations with decimal numbers, and by 19th century this word evolved into the word “algorithm”. Today, an English female mathematician “Ada Lovelace” (1815 – 1857) is considered to be the first computer programmer. Although there are descriptions of numerical algorithms from ancient Greece such as (Euclidean Algorithm), she has written the first algorithm in a modern computer science sense.
When algorithms are described, certain properties must be kept in mind:
Properties of Algorithms:
- INPUT: A set of values (strings, integers, webpages etc.) from a specific source.
- OUTPUT: This is the solution to the problem. The algorithm produces output values from the input values.
- DEFINITENESS: Each step of the algorithm must be precisely described.
- CORRECTNESS: The algorithm must produce the correct and desired outputs.
- FINITENESS: The number of steps of an algorithm must be finite.
- EFFECTIVENESS: It must be possible to perform each step of the algorithm in a precise method within a reasonable amount of time.
- GENERALITY: The whole procedure should be applicable for all the problems of the same type. If we have a procedure specifically designed just for a particular set of inputs, we can’t claim the procedure as an algorithm.
Example 1: Let’s consider a typical number problem: Finding the greatest number among given set of integers. Although this problem is relatively obvious, it will provide an illustration for the concept of an algorithm. (Note that, one could encounter this sort of problem every day, for example finding the best rated restaurant in the neighbourhood.) We would like to develop a certain method to achieve the task.
A Solution: Note that each step of the procedure must be precise enough so that a computer could “understand” and “follow”. Let’s perform the following steps:
- We start with the concept of temporary maximum, and we set it to be the first number in the sequence.
- We compare the next number in the sequence with the temporary maximum, if that number is greater than the temporary maximum then we update the temporary maximum to be that number.
- Repeat the previous procedure as long as there are numbers left in the sequence.
- Stop when there is no number left in the sequence, at this point the temporary maximum is the largest number in the sequence.
Here we use the English language to describe the procedure. The actual algorithm that can be interpreted by a computer with this logic depends on the programming language.
Whether this is an excellent solution or not is another question. That could be considered as the efficiency of the algorithm. There are certain mathematical calculations to measure the efficiency, but we will mention those later in a different post.
PageRank Algorithm
Here is an example of a more complex algorithm, so called PageRank© algorithm of Google. This algorithm was first introduced by Larry Page (co-founder of Google) in 1998. The name “PageRank” is a trademark of Google, the process has been patented which actually belonged to Stanford University. The university received 1.8 million Google shares for the use of the patent (all shares have been sold for 336 million US Dollars in 2005). We note that, this is just one of the factors determining Google Search results but still continues to provide a basis for Google’s web search.
The algorithm is used as a method of measuring how “important” a website is. It is based on the assumption that more important websites would be more likely to be linked by other websites. It basically measures the number and the quality of links to a certain page to determine an estimate how important a website is. It assigns a weighted numerical value to each website to determine the importance of the page and naturally more important websites appears earlier in the search results.
In the following simplified diagram, there are five websites, each arrow represents a link to the other page. The website in the middle, named “webpage”, is considered to be a “more popular” website, considering the fact that other pages are directing the user to that page.
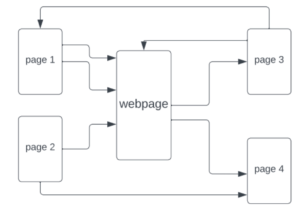
We note that not all pages have the same value, for instance if a webpage is linked by Wikipedia, that would be more valuable than a link from a newly established website.
We could explain the simplified algorithm recursively in the following way:
- The value of PageRank is initialized the same for all webpages:
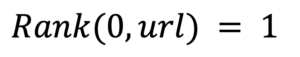
where 0 (zero) is the first step and “url” is the address of the website.
- Then all the links to this “url” are considered. We iterate the procedure with the following formula:

Here, we basically iterate the procedure to assign a numerical “importance” value to a certain website “url”, considering the number of links directing to this url and also, we need to keep track of the total number of links on a website (so that, the more links on a webpage there are, the less its weighted value will be).
Again, this is a simplified version of the actual algorithm, there are other normalizing factors in consideration. More detailed information can be found in references [1], [2], [4].
In words, we could roughly explain the procedure:
- A web surfer picks a website randomly, there might be several links on that page or maybe none at all (in that case pick another random webpage). Then the web surfer selects a random link on that page (if exists) and goes to the link.
- This procedure is applied over and over again, so the number of times we reach a certain page gives us an idea about how popular the page is (which is the number assigned by the formula above)
- Repeat the procedure periodically to update the importance of a website.
With this algorithm a source page (such as Wikipedia) having many citations (links directing to Wikipedia) would be one of the most important pages directly appearing in search results.
It looks a fundamental approach to solve the problem of setting a search engine. Surely there might be many other types of algorithms that could be used to surf the entire web. So, if you have a similar idea (perhaps even faster or more efficient) of an algorithm (plus a few billions of dollars) you might be some day a competitor of Google!
References:
[1] (Article) The Anatomy of a Large-Scale Hypertextual Web Search Engine by Sergey Brin and Lawrence Page. http://infolab.stanford.edu/pub/papers/google.pdf
[2] (Article) The PageRank Citation Ranking: Bringing Order to the Web http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
[3] (Book) Discrete Mathematics and Its Applications by Kenneth H. Rosen https://faculty.ksu.edu.sa/sites/default/files/rosen_discrete_mathematics_and_its_applications_7th_edition.pdf
[4] (Webpage) PageRank https://en.wikipedia.org/wiki/PageRank

