
Working in a consultancy company has the advantage of participating in several projects where different technologies are used to provide a solution for several use cases.
This lets us expand our perspective to solve problems, which is great, but with time is hard to keep up to date with all our colleagues on all the work we have done so far, due to being in different teams, projects, or just because we are mostly focused with our customer and we don’t have much time to chat.
But since we have a sharing knowledge culture at Data Insights, we thought of possible solutions for this. One was already covered by my colleague Hsiao-Ching in this blog post. And here we present another one that can be seen as a complementary part.
Considering our CVs has all the necessary information, we need a process to read and cluster it in the relevant groups like the technologies used, customers we have worked with so far, etc. After that, we can store this in our database of choice to query the results later in time.
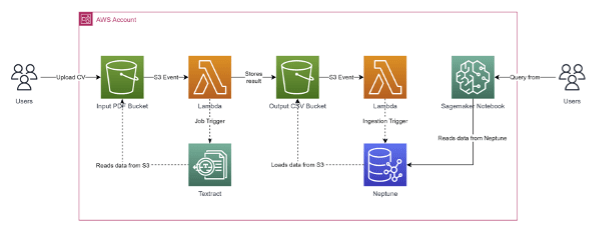
For this process, Amazon Textract is the perfect choice to gather the data from within the CVs, which are already in PDF format, though Textract also supports other formats. The first part of our process is to upload the files to S3. From there, a Lambda function is triggered in order to start the Textract job.
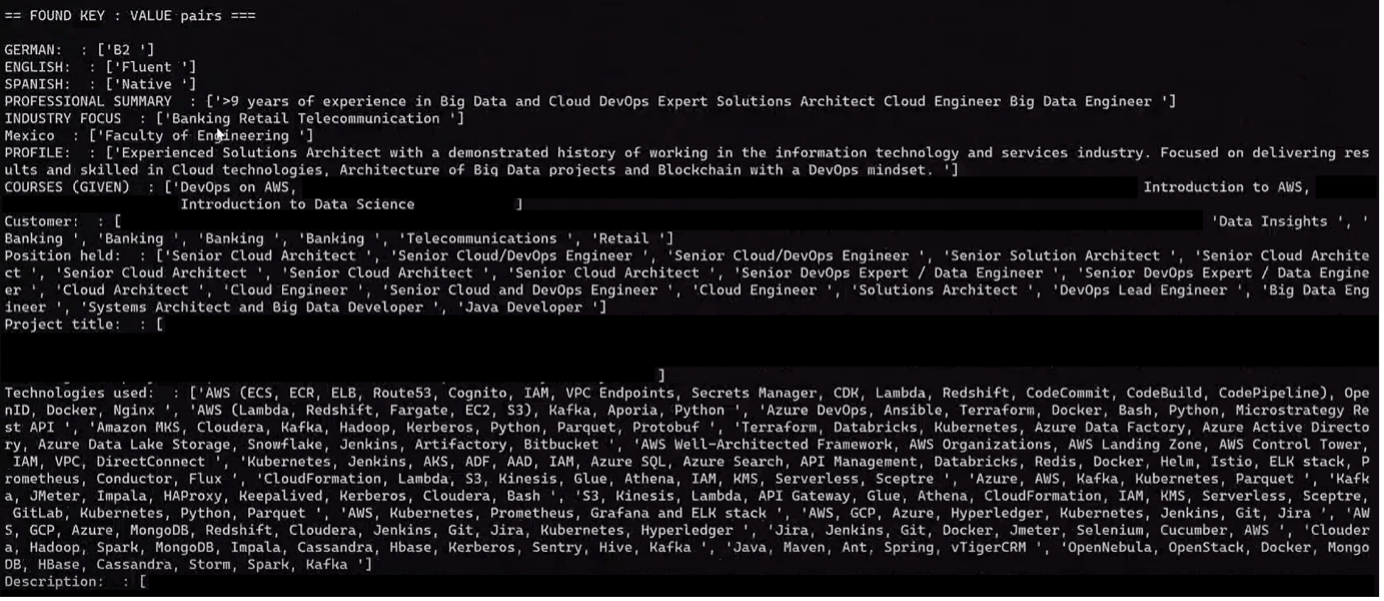
By using the feature of Form extraction, Textract automatically detects that the CVs have some information in common about the person, like the profile, customers, and technologies used, among others, and puts this information in key-values. After this, the function stores back the result in another S3 bucket in CSV format.
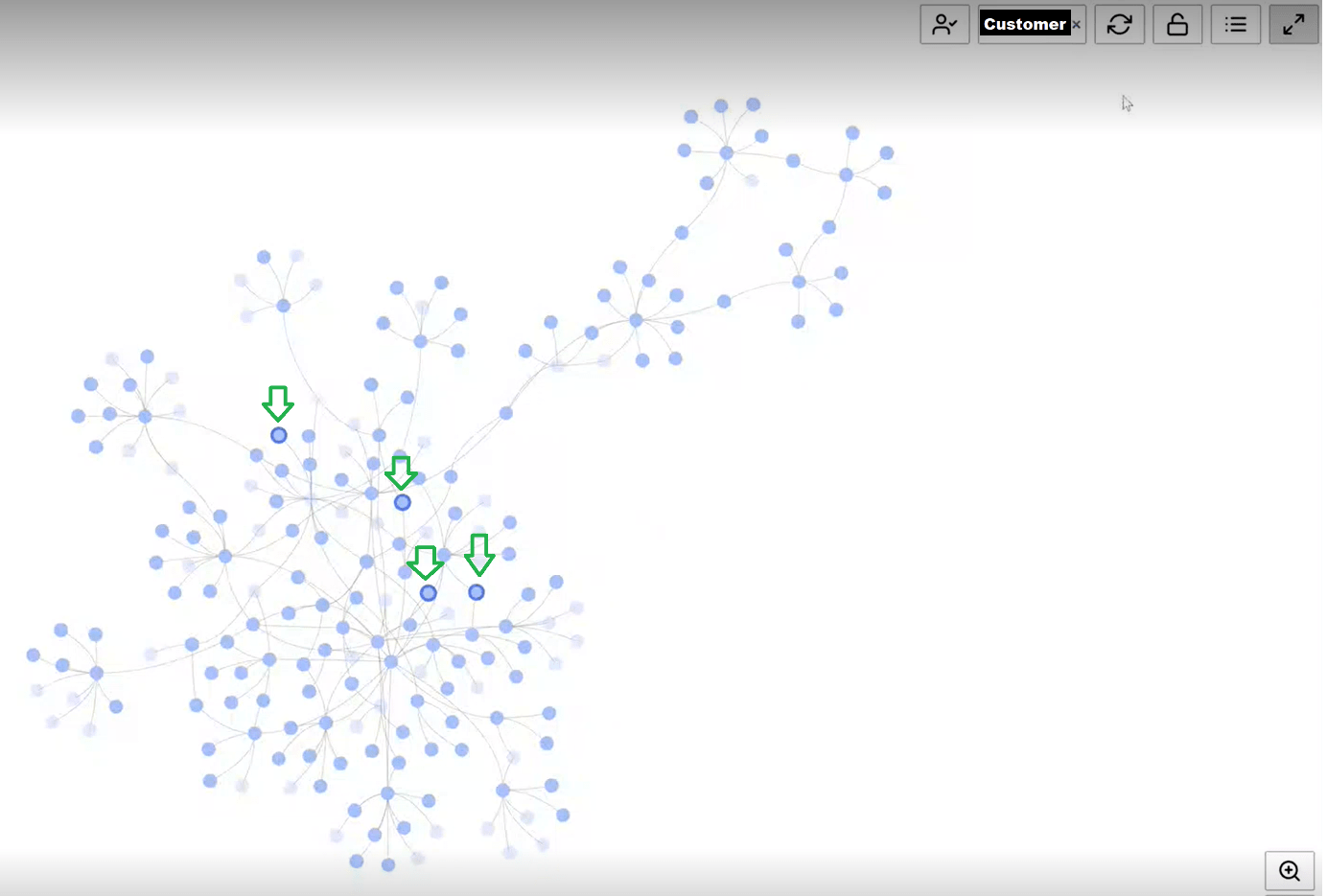
For the second part of the process, we use Amazon Neptune, as this will allow us to make queries in terms of the relationship of the data, like “give me all the colleagues who have worked with this technology or with this customer”.
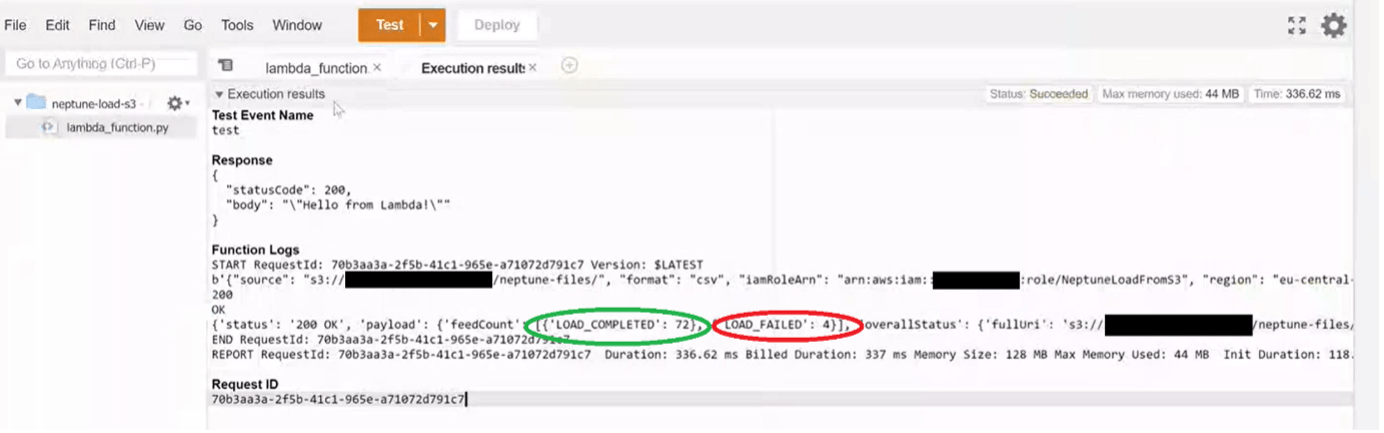
Then in order to ingest the data into Neptune, another Lambda function is triggered when the result from Textract arrives at S3. The ingestion is possible as the CSV data is in Gremlin load data format, but other formats are also supported, and this lets us do the ingestion in a bulk load fashion, instead of sending insert by insert, and by checking the status of the ingestion, we can see how many files failed to be ingested and need more preprocessing.
Once the data is loaded, by using a Sagemaker notebook, we can start to identify easily who can support us whenever we have a question about a specific topic, find common interests, or check which projects we can use as references for other ones.
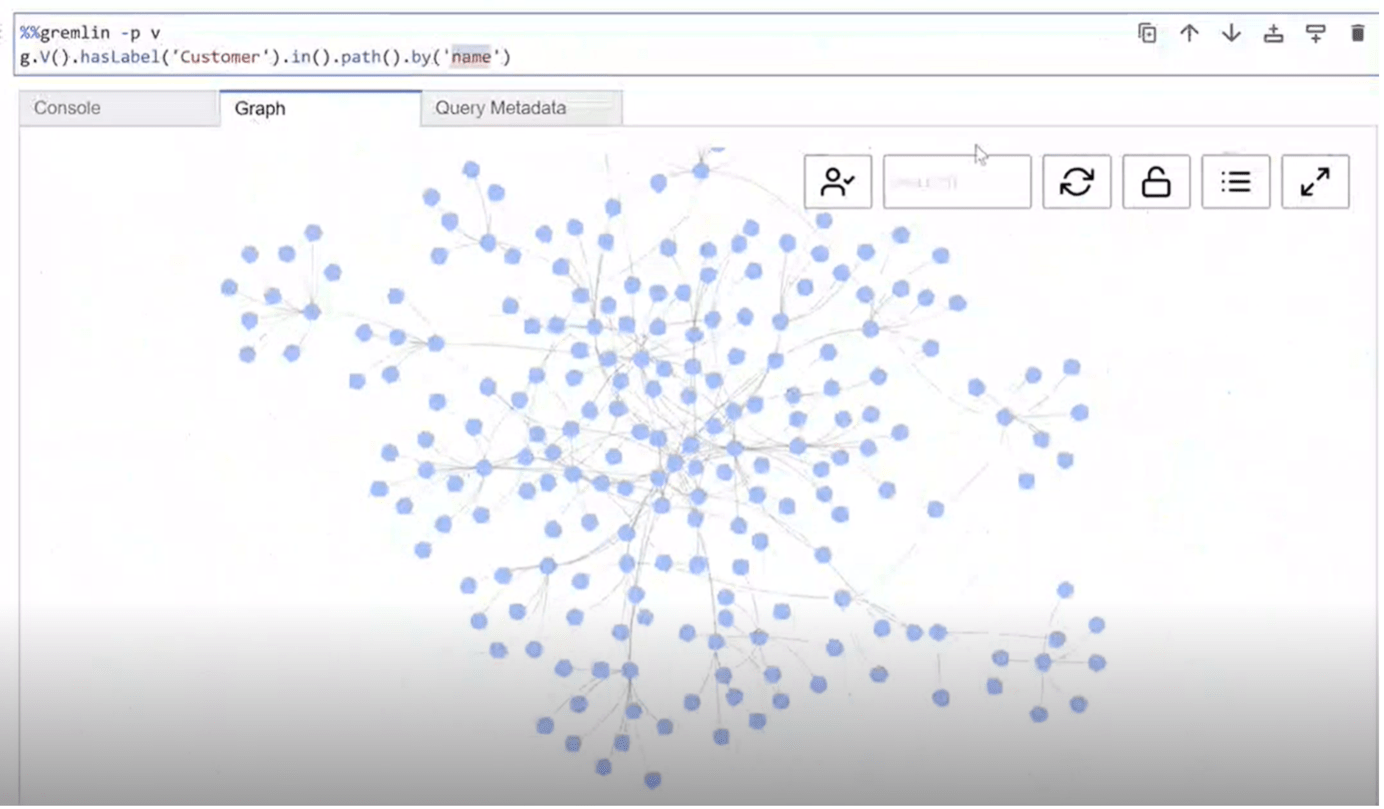
Finally, we can remark that this solution is completely serverless, as we don’t manage any infrastructure, and by just uploading the file, the process is automatically started. And as the next steps, we can further clean the information provided by Textract, in order to have a standardized output of values.

