
SAP is one of the most robust ERP systems used in sectors such as finance, supply chain management or manufacturing. It is recognized for its ability to optimize critical business operations. On the other hand, AWS is widely recognized as a strong and robust cloud space, offering solutions for storage, analysis and data processing.
Due to the strengths of these two platforms, it is natural for companies to seek the best of both worlds and establish a connection between them. Often, data stored in SAP needs to be transferred to AWS for back-ups, machine learning or some other advance analytics capabilities. Conversely, the information processed in AWS is frequently needed back in SAP system.
In this post we will explain different approaches to transfer data between these two platforms.
Using AWS Environment
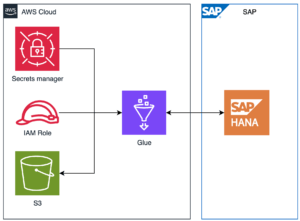
Connect AWS and SAP HANA using Glue
This entrance will show how to create a connection to SAP HANA tables using AWS Glue, how to read data from HANA tables and store the extracted data in S3 bucket in CSV format and of course how to read a CSV file stored in S3 and write the data in SAP HANA.
Pre-requisites:
-
HANA Table created
-
S3 Bucket
-
Data in CSV format (only to import data to SAP HANA)
-
SAP Hana JDBC driver
-
Components Creation
Secrets Manager
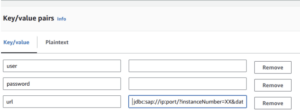
Let’s start with storing the HANA data for the connection in AWS Secrets Manager
-
user
-
password
-
url
*All this information should be provided by HANA system
Go to Secrets in the AWS console and create a new Secret, select Other type of secret and add the keys with the corresponding value.
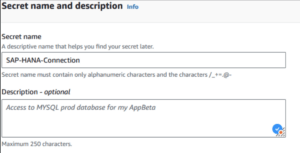
Go to next page and make sure to give this Secret a descriptive name, it is a good practice to also add a description, but this is totally optional.
IAM Role & policy
It is needed a role with access to the S3 bucket, Glue components and Secrets Manager data for the connection. AWS roles work with policies that are created separately and attached after. It is recommendable the creation in this order so we can add the minimum permissions needed for this process to work.
Policy creation
Under policy, click on create policy and select Secrets Manager, allow the following access:
-
GetSecretValue
Under Resources, make sure to add the ARN of the Secrets we created previously.
Add more permissions at the bottom and select S3, allow the following access:
-
ListBucket
-
GetObject
-
PutObject
Under Resources, make sure to add the ARN of the S3 Bucket where the data and driver connector are stored.
Add one more access for Glue and allow the following access:
-
GetJob
-
GetJobs
-
GetJobRun
-
GetJobRuns
-
StartJobRun
-
GetConnection
-
GetConnections
Under Resources, make sure to add the ARN.
In order to monitor our Job, we must add the permission for logs. Add CloudWatch Logs with the following access:
-
DescribeLogGroups
-
CreateLogGroup
-
CreateLogStream
-
PutLogEvents
Optional: You can use the predefined policy AWSGlueServiceRole instead, with this, the access to Glue and CloudWatch be allowed.
Role
To create the IAM Role, go to IAM in the AWS console and select Roles on the left panel, click on Create Role and select the AWS Service option.
Then, in Use Case section, select Glue, since this role will be mainly used for Glue.
The next step is to add permissions to our Role, for this it is recommended to use specific policies that includes the minimum accesses that our Role need, you can select the policy if you have it already created, otherwise you can just click on next and attach it once you created it.
In the next step we will be asked for the Name of this Role, here it is recommended to use a descriptive name such as SAP-HANA-DataTransfer-Role a good description it is also recommended, to explain the purpose of the Role.
Glue
Glue is a flexible tool that will allow to connect to SAP HANA using different methods, first I would like to point out that Glue counts with Glue Connector feature, which is an entity that contains data like user, url and password, this can also be connected to Secrets Manager to avoid exposing sensitive data. It is possible to summon this data in the glue job to add a layer of abstraction to the project. However, this is not the only way to create a connection, it is also possible to create the connection within the glue job using a JDBC driver, this is more transparent on how the connection is made, which can be useful in some scenarios.
Another feature of Glue is Glue Studio Visual ETL, with this feature you could develop an ETL process in a visual way, by using the drag and drop function you can select predefined blocks divided in three categories: Source, Transformation and Target.
The traditional way to create a Glue Job is with the Script Editor option, by selecting this option you get a text editor where you can code.
This document will present the following scenarios.
-
Glue Connection + Glue Job using Visual ETL
-
Glue Connection + Glue Job using Script Editor
-
Glue Job with embedded JDBC connection
Glue connection
The first step is to create a connection from AWS to SAP, for this we are going to use a Glue connector feature. On the left in the AWS Glue console, select Data connections and then Create connection.
This will open a wizard and will show different options for data sources, select SAP HANA.
Provide the URL and choose the secret created in previously.
Give a descriptive name to the connection and create the resource.
Glue Job
A Glue Job will be our bridge to connect to SAP Hana, as mentioned before there are different ways to create a Glue Job using the console, using Visual Editor and using Script Editor
Glue Connection + Glue Job using Visual ETL
Export HANA Table to S3
-
Create a Glue Job Visual ETL
-
Select SAP HANA in Sources
-
Select S3 in Targets
-
Add Custom Transform and select SAP HANA as Node Parent
-
Add Select from Collection and select Custom Transform as Node Parent
-
Configure the source:
-
On the right panel Data Source properties:
-
Select the SAP HANA connection
-
Provide the table to connect schema_name.table_name
-
-
Under Data Preview select the IAM Role created
A preview of the data contained in the table will be shown.
Configure the target:
-
On the right panel Data Target properties:
-
select the format CSV
-
Provide the S3 path where the CSV file is going to be stored
-
To avoid the content to split in multiple files, a transformation and selection are needed to condense everything into one single file.
-
-
Confirm that Amazon S3 has Select from collection as parent node
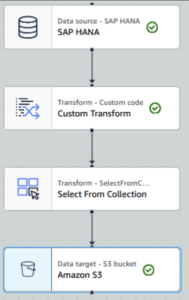
Add the code to the transformation module:
def MyTransform (glueContext, dfc) -> DynamicFrameCollection:
df = dfc.select(list(dfc.keys())[0]).toDF()
df_coalesced = df.coalesce(1)
dynamic_frame = DynamicFrame.fromDF(df_coalesced, glueContext, "dynamic_frame")
return dynamic_frame
Save & Run
Import CSV file to HANA
-
Create a Glue Job Visual ETL
-
Select S3 in Sources
-
Select SAP HANA in Targets
Configure the source
-
On the right panel Data Source properties:
-
Provide the S3 URL where the csv file is stored s3://bucket_name/prefix/file
-
Select CSV format and set the configuration according to your file
-
-
Under Data Preview select the IAM Role created
- A preview of the file content will be shown
Configure the target:
-
On the right panel Data Sink properties:
-
select Amazon S3 as Node Parent
-
Provide the table to connect schema_name.table_name
Note: If the table does not exist and your users has enough privileges, the table will be created.
-
Save & Run

Glue Job using Script Editor
-
Create a Glue Job Script editor
-
Select Spark as Engine
-
Select Start fresh and use the following code
> Export HANA Table to S3 – Using Glue Connection
##### Read from HANA
####Option 1
df = glueContext.create_dynamic_frame.from_options(
connection_type="saphana",
connection_options={
"connectionName": "Name of the connection",
"dbtable": "schema.table",
}
)
####Option 2
df = glueContext.create_dynamic_frame.from_options(
connection_type="saphana",
connection_options={
"connectionName": "Name of the connection",
"query": "SELECT * FROM schema.table"
}
)
##Condense into one single file
df_coalesced = df.coalesce(1)
#####Write CSV in S3
glueContext.write_dynamic_frame.from_options(
frame=df_coalesced ,
connection_type="s3",
connection_options={"path": "s3://bucket/prefix/"},
format="csv",
format_options={
"quoteChar": -1,
},
)
> Import CSV file to HANA – Using Glue Connection
Read CSV File
dynamicFrame = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={"paths": ["s3://bucket/prefix/file.csv"]},
format="csv",
format_options={ "withHeader": True,
},
)
###Write into SAP HANA
glueContext.write_dynamic_frame.from_options(
frame=dynamicFrame,
connection_type="saphana",
connection_options={
"connectionName": "Connection_Name",
"dbtable": "schema.table"
},
)
> Import/Export using JDBC Connection
####Export HANA Table to S3
df = glueContext.read.format("jdbc")
.option("driver", jdbc_driver_name)
.option("url", url)
.option("currentschema", schema)
.option("dbtable", table_name)
.option("user", username)
.option("password", password)
.load()
df_coalesced = df.coalesce(1) # to create only one file
df_coalesced.write.mode("overwrite")
.option("header", "true")
.option("quote", "\u0000")
.csv("s3://bucket_name/prefix/")
###Import CSV file to HANA
df2 = spark.read.csv(
"s3://bucket/prefix/file.csv",
header=True,
inferSchema=True)
# Write data in SAP HANA
df2.write.format("jdbc")
.option("driver", jdbc_driver_name)
.option("url", url)
.option("dbtable", f"{schema}.{table_name}")
.option("user", username)
.option("password", password)
.mode("append")
.save()
4. Go to Job Details
-
-
Give a name
-
Select the IAM Role
-
Advance properties
-
Add the SAP Hana Connection
-
-
-
Save & Run
Using HANA Environment
Exporting HANA tables to AWS S3
This documentation will show an option to export data from SAP HANA tables to S3 storage using a CSV file.
Pre-requisites:
-
HANA Table
-
S3 Bucket
-
AWS Access key & Secrets Key
-
AWS Certificate
Configure AWS Certificate in HANA
It is needed to add an AWS certificate as a trusted source in order to export the data.
-- 1. Create certificate store SSL
CREATE PSE SSL;
-- 2. Register S3 certificate
CREATE CERTIFICATE from 'AWS Certificate Content' COMMENT 'S3';
-- 3. Get the certificate ID
Select * from certificates where comment = 'S3';
-- 4. add S3 certificate to SSL certificate store
ALTER PSE SSL ADD CERTIFICATE CERTIFICATE_NUMBER; -- the certificate number is taken from select statement result in step 3.
SET PSE SSL PURPOSE REMOTE SOURCE;
Export Data – GUI Option
SAP software has the option to export data to several cloud sources by right-clicking on the desired table to export.
It shows a wizard to select:
-
Data source: Schema and Table/View
-
Export Target: Amazon S3, Azure Storage, Alibaba cloud
-
Once we select Amazon S3, it will ask for the S3 Region and S3 Path. This information can be consulted in AWS Console, in the Bucket where we want to store our exported data.
-
By clicking on the Compose button it’ll show a prompt to write the Access Key, Secret Key, Bucket Name and Object ID
-
![]()
-
Export options: It defines the format CSV/PARQUET and configuration of the CSV file generated.
Finally we can export the file by clicking on Export button and it should be uploaded in our S3
Export Data – SQL Option
However, we’ll get the same result if we run from the SQL console in SAP HANA the following query:
EXPORT INTO 's3-REGION://ACCESSKEY:SECRETKEY@BUCKET_NAME/FOLDER_NAME/file_name.csv' FROM SCHEMA_NAME.TABLE/VIEW_NAME;
It is possible to import CSV files stored in S3 by using the IMPORT Statement
IMPORT file_name 's3-REGION://ACCESSKEY:SECRETKEY@BUCKET_NAME/FOLDER_NAME/file_name.csv';
Conclusion
It is possible to have the best of both worlds by using these solutions. The solutions mentioned can be applied in different circumstances, the process of exporting data using SAP system is advisable when a direct connection its needed to offload datasets for backups or data lake solutions. This allows to get a better cost control since the storage in S3 can be easily controlled with the different types of storage tiers exiting in AWS.
On the other hand, using AWS Glue is convenient when an automated process of the extraction of the data is required, in addition, Glue can transform and load the data into S3 where it can be processed for machine learning or data warehousing.
In summary, combining SAP HANA’s export capabilities with AWS Glue’s data transformation tools enables efficient and scalable data management.

