
Introduction
Nowadays, when you start talking about data, you will frequently come across two main terms; structured and un-structured. Many times, also the term semi-structured, and sometimes the term poly-structured. Sometimes, you will hear that data are repetitive or non–repetitive. There are many more terms you will potentially hear, but for the moment let’s stick with these and give them a definition.
Detailed explanation and some examples can be found in a very good book I read and I would recommend to you: “Data Architecture: A Primer for the Data Scientist: Big Data, Data Warehouse and Data Vault”. This book was written by two very well-known people active in the data area: The father of the data warehouse W. H. Inmon (Author), and the inventor of the data model, “Data Vault”, Daniel Linstedt.
Q: Why is it important to talk about the data structures, again?
A: The answer is due to their importance!
In conjunction to the structure of data there is a very important hypothesis: “80% of the company data are unstructured data and this data contain the highest business value.”
If you don’t want to read the book, here you can find some explanation and find some examples,:
- http://www.ibmbigdatahub.com/blog/unstructured-and-structured-data-versus-repetitive-and-non-repetitive-data
- https://www.ibm.com/blogs/watson/2016/05/biggest-data-challenges-might-not-even-know/
Or Just think about some current use cases, which became real over the last years/months
- the automotive industry and the use case of “autonomous driving”
- Amazon just lunched GO (the supermarket to go).
- Or intelligent Bots used for several different services
These potential successful products/services and many more will generate billions of revenues using unstructured data.
Or simply google it 😉 http://lmgtfy.com/?q=business+value+of+unstructured+data
So, personally I think we are not talking about a hypothesis anymore. It’s a fact.
But for now, I will summarize the whole story.
Summary
Corporate Data
Organizations are interested in all the data which have a business value for them. Organizations own data outside and inside the company, and we learned 80% of them are unstructured.
Hence, all types of data which contain any business value are so called “Corporate data” from the organization’s perspective.
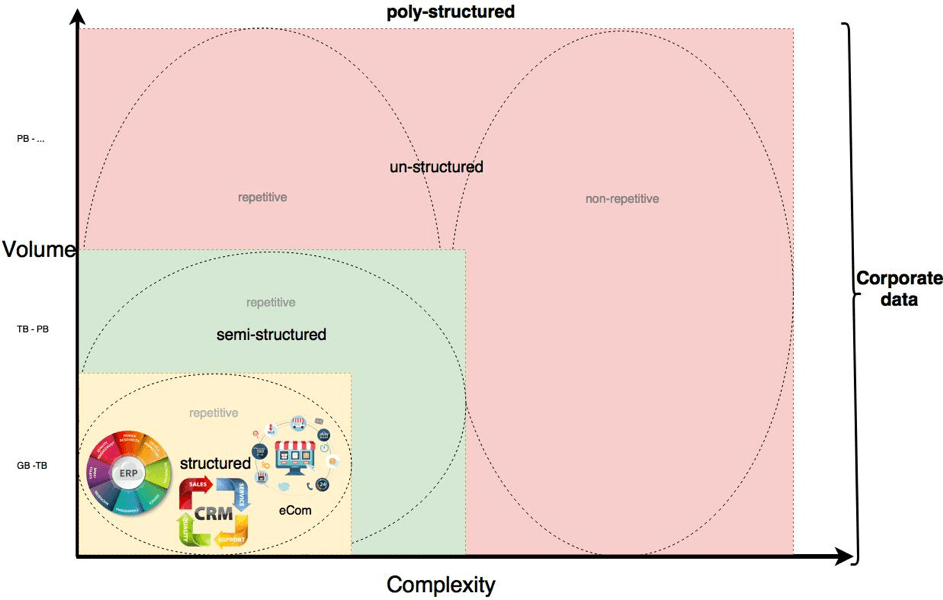
The following picture illustrates corporate data from a complexity and volume perspective, structured according to the commonly used categories/terms.

| Question | Structured data | Semi-structured data | Unstructured data |
| Q: What does * data mean? | A: structured data means, data which have a specific schema and these schemas are represented in a data model! Typically, structured data can be found in relational databases and the schema of the data is the table structure and the data model are all the tables and their relations. | A: Semi-structured data is data that has not been organized into a specialized repository, such as a database, but that nevertheless has associated information, such as metadata, that makes it more amenable to processing than raw data (unstructured data). | A: this refers to data that either does not have a pre-defined data model, or is not organized in a pre-defined manner. Unstructured data is typically text-heavy, but may contain data such as dates, numbers, and facts as well. Sound, videos and images also belong to the category of unstructured data. |
| Q: Can the schema and the data model change over time? | A: Yes, schemas and data model can change over time, but all functions which writes or reads data into these schemas needs to be modified respectively. Schemas and data models are basically static for a certain period, and any kind of changes affect a new version of the schemas and data model, which are then static for the new period. | A: as mentioned before, semi structured data are not based on a schema or structure, but the schema and structure can be derived from it and each record/entry might be different. So the simple answer is no schema and data model. | A: in reference to the above answer, there is no schema since it has no data model or is not organized. Consequently, there is no schema and no data model which can change over time. |
| Q: How can I read or write data into a schema? | A: Structured data is often managed using Structured Query Language (SQL) – a programming language created for managing and querying data in relational database management systems. Additionally, programming languages like java, c++ etc. and functional programming languages like scala, python, r etc. can be used. | A: more and more, semi-structured data can be managed using Structured Query Language (SQL) – a programming language created for managing and querying data in relational database management systems. The SQL language is getting extended more and more to also query semi-structured data like json or xml. Nevertheless, programming languages like java, c++ etc. and functional programming languages like scala, python, r etc., provide you with the full flexibility and possibility to read and write semi-structured data. | A: programming languages like java, c++ etc. and functional programming languages like scala, python, r etc. can be used. Frameworks like caffe, tensor flow etc. for images etc. |
| Q: How big are data typically? | A: structured data are in the area of Giga byte (GB) and Terabyte(TB) | A: semi-structured data are in the area of Terabyte(TB) and Petabyte (PB) | A: un-structured data are in the area of Petabyte (PB) and above |
Repetitive and non-repetitive Data
Repetitive data are based on processes, and since processes are repeated all the time, the data are repeated in their structure and values.
Non-repetitive data are text, image, video or sound heavy. Each part is unique and not being repeated. Non-repetitive data are mainly located in the unstructured data area, while repetitive data are located in all 3 data areas.

Data types per example
Structured data
The most well-known structured data are
- CRM
- ERP
- eCommerce
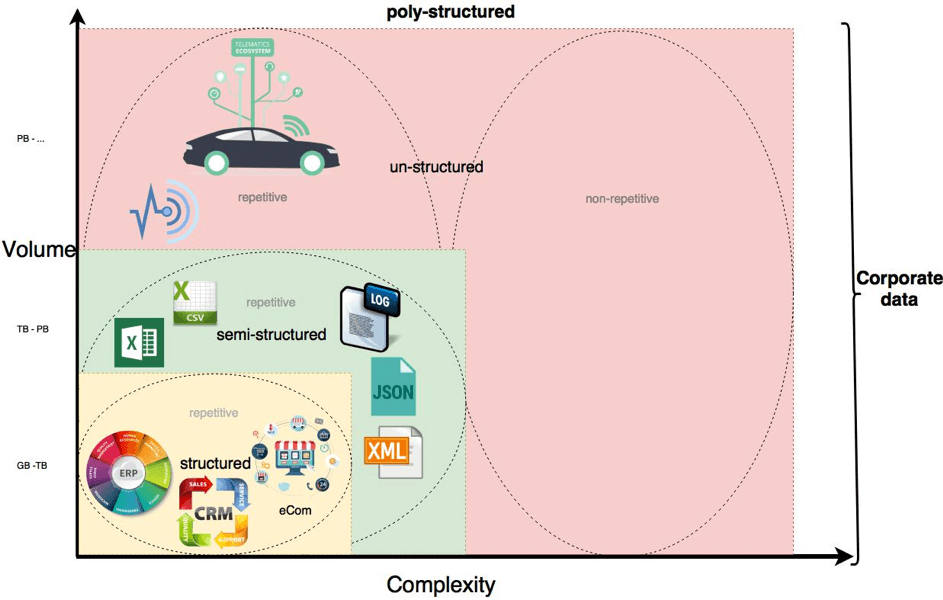
Semi-structured data
The most well-known semi-structured data are
- usage, web and server logs
- JSON
- XML
- Excel, CSV etc.

Unstructured data (repetitive)
The most well-known repetitive structured data are
- Sensor and telematics
Unstructured data (non-repetitive)
The most well-known non-repetitive structured data are
- Social and business media
- Documents and emails
- Videos and images
- Sound

| Question | Structured data | Semi-structured data | Unstructured data |
| Q: Where are these data nowadays accessible and how are they used? | A: Nowadays, structured data are mainly collected and transferred in a traditional data warehouse for reporting and BI. Since a few years these data are fully collected and transferred in so called Data Lakes for exploration and analytics (Data Science) in conjunction with the other types of data. | A: Nowadays, semi-structured data are partially collected and transferred in a traditional data warehouse for reporting and BI. Since a few years these data are fully collected and transferred in so called Data Lakes for exploration and analytics (Data Science) in conjunction with the other types of data. | A: Nowadays, unstructured repetitive data are partially (just a small subset) collected and transferred in a traditional data warehouse for reporting and BI. Unstructured non-repetitive data are mostly not collected and transferred in a traditional data warehouse for reporting and BI. Since a few years unstructured data are fully collected and transferred in so called Data Lakes for exploration and analytics (Data Science). |
Conclusion
Lots of data (from a volume and structure perspective) are not accessible over traditional approaches like traditional data warehouses due to many different issues
Since poly-structured and especially unstructured data do have big business value as we learned and an approach is needed to
- Understand the business value exploring the data
- Integrate the data (all types) to make them accessible
- Implement so called data driven products
Since a few years all types of data (ploy-structured data) are or may be collected and transferred in Data Lakes.
Since we designed and implemented already many data lakes, I will explain the architecture of Data Lakes we build in another blog and its not reflected here.
Before explaining how a data lake architecture looks like to make all these data accessible and usable, the data landscape process can help you to to understand
- which use cases are from interest and which one potentially in the future
- which data you need for the use cases
- which complexity in respective to corporate data you have
- how much value you know about the corporate data
- what you want to achieve short/mid and longterm
- which technologies you need to achieve your goals
So, in the next blog I will explain the data landscape process to prepare the story of data architectures.

