
Python has gained immense popularity in the data stack space, largely due to its rich ecosystem of libraries. Among these, Dataframe libraries play a pivotal role in simplifying the process of working with data. Dataframes are one of the most common data structures used in modern data analytics – they organize data into 2-dimensional tables of rows and columns, similar to spreadsheets or SQL tables.
Here we will explore some of the most common Dataframe libraries in Python, their key features, and use cases. Whether you are a data scientist, data engineer, or Python enthusiast, this guide will help you navigate through the myriad options available to efficiently handle your data.
Pandas
We cannot talk about Dataframes and Python without starting with Pandas. It was developed in 2008 by Wes McKinney and today is one of the premium open-source data science libraries. Pandas enables us to write fast, flexible and expressive data structures, designed to work with relational or labeled data, easy and intuitive.
Pandas is great! It does a lot of things well:
- Automatic and explicit data alignment, handling of missing data for many data types, size mutability
- Groupby and powerful split apply functionality for aggregating and transforming
- Intelligent indexing features, intuitive and flexible joining, reshaping and pivoting operation
- I/O tools – reading and writing from and to different sources
- Time-series – window statistics, date shifting, etc.
As the amount of data to analyze has grown, so has Pandas’ old architecture started to show it’s limits. Even it’s creator has admitted as much. After 5 years of development and learnings, in 2013 Wes McKinney wrote about 11 things he hates about Pandas:
- Internals too far from “the metal”
- No support for memory-mapped datasets
- Poor performance in database and file ingest / expor
- Warty missing data support
- Lack of transparency into memory use, RAM management
- Weak support for categorical data
- Complex groupby operations awkward and slow
- Appending data to a Dataframe tedious and very costly
- Limited, non-extensible type metadata
- Eager evaluation model, no query planning
- “Slow”, limited multicore algorithms for large datasets
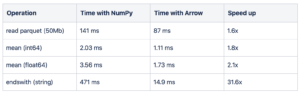
Speed comparison by Marc Garcia
To solve these issues Pandas development has shifted to Apache Arrow, as a key technology for the next generation of data science tools. Currently, Pandas 2.0, based on the Arrow backend, fixes a lot of those points (notably 3, 4, 5, 6, 8, 9) and continues to develop. Version 2.0 brings better interoperability, faster speeds, and representation of “missing data” to Pandas. For single compute workloads up to 10 GB Pandas is still a great choice with the biggest community.
Side note: Apache Arrow
Apache Arrow is a development platform for in-memory analytics. It contains a set of technologies that enable big data systems to store, process and move data fast. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. The project is developing a multi-language collection of libraries for solving problems related to in-memory analytical data processing. This enables us to have a unified translation layer between different implementations of common data structures.
PyArrow are the Arrow Python bindings and have first-class integration with NumPy, Pandas, and built-in Python objects. They are based on the C++ implementation of Arrow.

Where Arrow has become the defacto standard for representing tabular data, other projects have risen to enable the standardization of data handling in numerical computing, data science, machine learning, and deep learning. One of those projects is Substrait – it is a universal standard for representing relational operations, and will complement Arrow in future interoperability of data systems.
Most other Dataframe libraries mimic Pandas API, due to its popularity, but others adopt new, distributed concepts to help with the data processing logic. With an aim to tackle the fragmentation in Array and Dataframe libraries, the Consortium for Python Data API Standards was established. It’s a partnership across industry to establish cross-project and cross-ecosystem alignment on APIs, data exchange mechanisms, and to facilitate coordination and communication.
Pandas inspired a whole ecosystem of libraries, and here we present some of the noteworthy ones.

Polars
Polars is a Dataframe library built in Rust on top of a OLAP query engine using Apache Arrow as the memory model. It has no indexes, supports both eager and lazy evaluation, a powerful expression API, enables query optimization, it is multi-threaded and much more. Polars is how Pandas would look if it was implemented today. The cons of Polars are exactly that – it is still young so does not yet have all the features of Pandas, nor the ecosystem that grew out of it. Some notable missing features are the visualization API, absence of Pandas dot notation, dtype efficiency, as well as general compatibility issues.
What Polars lacks in features it makes up in speed. Benchmarked against competitors in reading and analytical processing Polars is a clear winner. Although it’s young, for non-critical projects, Polars would today be my choice for Pandas use-cases.

Dask
Dask is a flexible parallel computing library, a task scheduler, that seamlessly integrates with Pandas. It extends Pandas’ capabilities by enabling it to handle datasets that don’t fit into memory. Dask Dataframe provides a familiar Pandas-like interface while distributing computations across multiple cores or even clusters. It allows you to scale data analysis tasks, making it an excellent choice for handling large datasets and performing distributed computing. Under the hood it’s still Pandas, but optimized for distributed workloads. Depending on the algorithm and use case, it can be a better choice than Spark – and definitely cheaper and easier to maintain.
Vaex
Vaex is a high-performance Dataframe library designed for handling large-scale datasets. It is specifically optimized for out-of-core computations, allowing you to work with datasets that are larger than your available memory. Vaex is built to efficiently execute calculations on disk-resident data, making it significantly faster than Pandas 1.x. It uses HDF5 to create memory maps that avoid loading datasets to memory, as well as implementing some parts in faster languages. It is mostly used to visualize and explore big tabular datasets.
Modin
Modin is a modular Dataframe library that aims to provide a faster Pandas replacement by utilizing distributed computing frameworks like Dask or Ray. It allows you to seamlessly switch between using a single machine or a distributed cluster without changing your code. While Pandas is single-threaded, Modin lets you instantly speed up your workflows by scaling Pandas so it uses all of your cores. Modin retains the ease-of-use and flexibility of Pandas while providing significant performance improvements, especially when dealing with large datasets. The API is so similar to Pandas that Modin calls itself a drop-in replacement for Pandas.
cuDF
cuDF is a GPU Dataframe library built on top of Apache Arrow. It provides an API similar to Pandas, so it can be easily used without any CUDA programming knowledge. End-to-end computation on the GPU avoids unnecessary copying and converting of data off the GPU, reducing compute time and cost for high-performance analytics common in artificial intelligence workloads.
PySpark
PySpark is the Python API for Apache Spark, the analytics engine for large-scale data processing. It supports a rich set of higher-level tools including SparkSQL for SQL and Dataframes, Pandas API on Spark for Pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.
Pandas API for Spark provides a Pandas-like interface on top of Apache Spark, allowing you to leverage the scalability and distributed computing capabilities of Spark while enjoying the ease of working with Dataframes. PySpark has for years been the king of distributed data processing.
Datafusion
Datafusion is a very fast, extensible query engine for building high-quality data-centric systems, using the Apache Arrow in-memory format, and offering SQL and Dataframe APIs. It is more popular in the Rust community, and such best used in need of interoperability needed between Python and Rust.
Ibis
Ibis is a high level Python library that provides a universal interface for data wrangling and analysis. It has a Pandas-like Dataframe syntax and can express any SQL query, supporting modular backends for query systems (Spark, Snowflake, DuckDB, Pandas, Dask, etc). Another important part of it is differed execution, so execution of code is pushed to the query engine, boosting performance.
It is especially good as an interface for multiple query engines, since it unifies the syntax. As such it shines when you want to use the same code with different backends.
DuckDB
DuckDB is an in-process SQL OLAP database management system. The reason why it’s been mentioned in the same category is because it can efficiently run SQL queries on Pandas Dataframes, and can query Arrow datasets directly and stream query results back to Arrow. This enables us to use the benefits of Arrow and parallel vectorized execution of DuckDB in one. It is a no hassle DBMS and a clear choice for prototyping with SQL.
Conclusion
Dataframe libraries in Python play a crucial role in simplifying the process of working with structured data, offering powerful tools and efficient data manipulation capabilities. Whether you prefer the versatility of Pandas, the scalability of Dask and Vaex, the distributed computing capabilities of Modin, or the seamless integration with Apache Spark provided by PySpark, Python offers a diverse range of options to suit your data analysis needs.
Understanding the strengths and use cases of these libraries can significantly enhance your productivity and allow you to handle datasets of varying sizes effectively. With the rise of Arrow types, converting between them will be almost immediate, with little metadata overhead. Happy datalyzing!

