
Introduction
Apache Hudi, Apache Iceberg, and Delta Lake are state-of-the-art big data storage technologies. These technologies bring ACID transactions to your data lake. ACID is an acronym that refers to 4 properties that define a transaction:
Atomicity: Every transaction is treated as a single unit.
Consistency: Every transaction’s result is predictable and there are no unexpected results.
Isolation: Manage the concurrent access or change of the table. The concurrent transactions don’t interfere with each other.
Durability: The changes are saved even though the system fails.
We have developed a configurable framework where we can test the three technologies purely through parameters, without needing to change the code. The benchmarking of these three technologies was done on AWS EMR and the data was stored on AWS S3.
The analytics engine used in our project is Apache Spark. The open-source versions of these technologies were used—concretely Apache Spark 3.1.2, Apache Hudi 0.10.1, Apache Iceberg 0.13.1, and Delta Lake 1.0.0.
Apache Hudi (Hadoop Upserts Deletes and Incrementals)
Apache Hudi was initially developed by Uber in 2016 and open-sourced in 2017. It was contributed to the Apache software foundation in 2019. It fully supports Spark in reading and writing operations. Hudi is the trickiest technology that we used in our project. The tuning of Hudi table options is crucial. The choice of these options can boost performance or decrease it drastically.
There are mainly two different types of Hudi tables:
Copy-on-Write tables (CoW): Data here is stored in a Parquet format (a columnar file format) and each update creates new files during write. This type of table is optimized for read-heavy workloads.
Merge-on-Read tables (MoR): Data here is stored in both Parquet and Avro formats. The Avro format is a row-based file format. Writing performance using Avro is better, but reading performance is decreased.
By default, Hudi uses CoW tables, but this can be changed easily. Even though writing performance is better in MoR tables, we have used the CoW tables in our project. When trying to update or delete a lot of rows of a Hudi MoR table, we have noticed some irregular behavior, which we will describe below
There are two operations to insert records into a Hudi table. A normal insert and a bulk insert. The latest scales very well for a huge load of data.
The metadata is stored in a folder generally called .hoodie. In fact, all the information about save points commits, and logs is stored there.
Apache Iceberg
Iceberg was initially released by Netflix. It was donated to the Apache Software Foundation later. The version that we used fully supports Spark. Older versions have problems using Spark in terms of performance, so we recommend that you use the latest version of Iceberg. Additionally, Iceberg is becoming faster. Compared to older versions, it became much quicker lately.
Data files are created in place in Iceberg. This means that data is not changed, but new ones are created. When we change a file, a new one is created with the changes. Iceberg tracks individual data files in a table. Every snapshot tracks the files that belong to that snapshot and ignores the other files. The state of the table is saved in a metadata file. With every change to the table, a new metadata file is created that replaces the old one. In this file, a lot of pieces of information are stored related to the table, such as the schema and other properties and configurations. Snapshots are listed in the metadata and it points to which snapshot is used right now. The files that a snapshot tracks are stored in a manifest file. Every snapshot has its manifest file. This provides total isolation of snapshots.
Delta Lake
Delta Lake was initially maintained by Databricks. It is donated to the Linux foundation and it was recently open-sourced completely. It is an open-source project and it provides deep integration with Spark in reading and writing operations since Spark was initially created by Databricks. Delta uses metadata just like Iceberg and Hudi. The metadata is called delta logs and for every commit, a JSON file is created in which the operations done in that commit are recorded so they can be reverted easily while time traveling. A parquet file is created as a checkpoint file after a certain number of commits (generally 10). The previously generated JSON files are rewritten into that parquet file to optimize access to the logs.
Benchmarking
We have used an emr-6.6.0 cluster with one master node and two worker nodes. All of the nodes are m5.2xlarge. We have used the Spark History Server to do the benchmarking and calculate the execution time. We generated some random data and stored them in Json format on an s3 bucket. We used these files to do the benchmarking. We have gotten the following results:
Sizes of Resulting Tables

The resulting sizes of the iceberg tables are the smallest and this will lead to a huge optimization in terms of storage in the long run. Delta and Hudi (bulk insert version) are very close in terms of size with a small advantage over Hudi. The biggest tables are Hudi tables using the normal insert operation. However, it throws errors and exceptions under a heavy workload.
Insert Operation
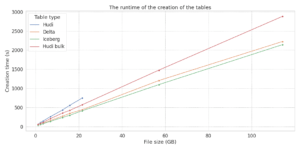
The performances of Iceberg and Delta are the best in terms of the performance of the creation of the tables. Iceberg is a little bit faster than Hudi. Hudi is the worst with its own 2 versions. Normal inserted Hudi tables have the same problems as mentioned above.
Update Operation
We have conducted the update benchmarking in two steps.

First, we tried updating only 10% of the records. Iceberg is incredibly faster than Hudi and Delta. We have used Hudi tables that were created using bulk insert operation since we had problems creating them using normal insert. At first, Hudi was faster than Delta but with the increase in data size, Delta became slightly faster.
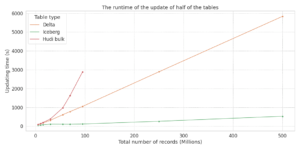
After noticing that Hudi becomes slower with the increase in size, we decided to test updating 50% of the records. Iceberg is always much faster than Hudi and Delta. We noticed that with a high workload Hudi becomes slower. In this case, Delta is faster than Hudi. Hudi’s runtime of updating half of the record grows exponentially and it throws errors at a certain threshold.
Remove Operation
Just like the update operation, we had done two tests using remove.

We removed 10% of the records of every table and we have noticed that, as always, Iceberg is far away more performant than Delta and Hudi. Hudi in this case is much faster than Delta.
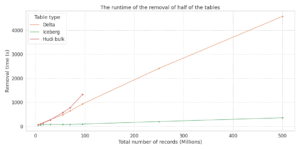
We wanted to check the pattern of Hudi after removing half of the tables. As expected and just like the update operation, Hudi became the slowest of all technologies and Iceberg stayed the fastest. Hudi’s runtime grew rapidly until it threw exceptions just like an update.
Conclusion
We have found that Iceberg, with the configurations we have done, is the most performant technology. The resulting sizes of the iceberg tables are the smallest and this will lead to a massive optimization in terms of storage in the long run. Additionally, insert, upsert, and delete operations are most optimized using Iceberg. Iceberg technology is considerably faster than Hudi and Delta.
The performances of Hudi and Delta are close. The thing that we noticed is that under a huge amount of workload Hudi throws some errors and exceptions related to some timeout and this may be related to the complex configuration that Hudi needs to function perfectly. The bulk insert operation throws fewer exceptions than the normal insert operation in Hudi.
These results depend on the configuration of these technologies, especially Apache Hudi. It can vary a lot. We can consider these results insights into what to expect from each technology.
Our project was based on a data processing framework, developed by us, that offers a pattern to separate an ETL process extraction, transformation, and loading logic. We will write a blog post about it soon!
References:
Comparison of Data Lake Table Formats (Iceberg, Hudi, and Delta Lake)
Hudi, Iceberg and Delta Lake: Data Lake Table Formats Compared
Using Iceberg tables – Amazon Athena
Hello from Apache Hudi | Apache Hudi

