
What the heck is a GAN?
One longstanding problem in AI is figuring out the best way to generate realistic content. How can you teach a computer to create images, videos, text, or music indistinguishable from human-generated equivalents? In 2014, a group of researchers at the Université de Montréal had a fairly quirky idea regarding how to address this problem. Why not create two AI programs: one would repeatedly try to generate human-level output, while the other would try to distinguish between human-generated and machine-generated content. The resulting architecture was given the name “Generative Adversarial Network”, or GAN for short (https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf).
The concept worked splendidly well: within a few years GANs were able to generate stunningly realistic images. For example, human faces which were indistinguishably authentic
(https://thispersondoesnotexist.com/).
The advent of GANs was especially fortuitous for another reason. In 2018 the world was introduced to Edge TPU (Tensor Processing Units). Analogous to how GPU excelled at Graphical Processing, and CPUs at Computing, TPUs are designed to facilitate Tensor operations. This is entirely inspired by ML: tensor operations form the core of ML processes. On a larger scale, the outcome of Edge TPUs is that ML operations can now be run on edge devices (think phones, tablets, personal computers, and small-scale on-prem computing facilities in hospitals, warehouses, etc.). With Edge TPUs, ML training is not only faster, but also more energy efficient.
This shift towards “ML on the Edge” is partly the result of Edge TPU infrastructure, but it also demonstrates a reaction towards recent data privacy developments. The massive implications of the 2016 adoption of GDPR legal infrastructure have made it clear that huge corpuses of user-surrendered training data may no longer be legally feasible. Companies will have to adapt to these new limitations. There are two such ways to accomplish this. Companies can turn towards Federated Learning, in which small models are trained on edge devices, and then aggregated at a central point. Data need not leave the edge devices.
Another method is through the creation of synthetic data. GANs can take a small sample of data – collected from either consenting users, or a dev team – and use it as a blueprint for generating much more data. This synthetic GAN-generated data can then be used to train subsequent ML models (see, for example, https://arxiv.org/abs/1909.13403)
The uses of GANs do not end simply at synthetic data generation. They can automate many complex data manipulation processes, leading to a number of potential use cases. To list a few examples:
- Google Maps uses GANs to generate simple map images from complex satellite data.
- Fashion retailers can use GANs to automatically dress potential customers in prospective clothing purchases using an uploaded image.
- GANs can identify faces in images, and learn to blur them for data anonymization applications.
- GANs can improve video, image, or audio quality. This can include colouring old photos, improving the frame rate of old videos, or even pushing the resolution of media past that it was captured in (super-resolution).
Data Insights was therefore eager to try out such a new and promising technology. So we took it for a spin.
The Idea
The internet is littered with videos of techies showing off “ML Invisibility Cloaks”.
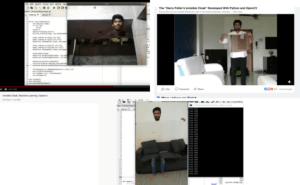
A cloth is held up, and amazingly the person holding it vanishes! As magical as this seems, it’s nothing new, and does not incorporate ML. This is the timeless “green screen” effect, which has been used in movie production since the 1950s, back when ML was nothing more than a distant pipe dream. In a nutshell, a picture of the background without the person is overlaid by an identically framed video in which the person walks around and holds a green cloth. A filter eliminates all green pixels, and the background image comes through.
The point here is that the program already knows what is behind the person, making the claim of a Harry Potter style Invisibility Cloak feel a little overblown. But then, one may ask, could it be possible to somehow “know” what is behind a person, without having any information? That is: true invisibility?
Well, ultimately, no. You can never be truly sure what lies behind somebody without having seen it previously (barring perhaps gravitational lensing, and a few other extreme cases). But, as Photoshop has taught us, we can do a pretty good job at guessing. In fact, long before Photoshop, expert photo manipulators could convincingly edit somebody out of a photo. Take this infamous example of Soviet secret police official Nikolai Yezhov.

After falling out of favour with Stalin during the purges of the 1930s, Nikolai was executed, and his presence in photos was carefully doctored away. Putting aside the macabre nature of the example for the more technical considerations, one can see how the editor has inferred the continuation of the low wall on the right, as well as repeating the pattern of ripples in the water. The question arises: could a GAN learn to automate the same process?
Training a GAN Invisibility Cloak
To attempt this, we opted for the pix2pix GAN architecture introduced in 2017: https://phillipi.github.io/pix2pix/
As training data, pix2pix expects pairs of photos with an exact pixel-to-pixel (hence the name) correspondence between what is input, and what is desired as output. To create such a dataset, we scoured the web for stock photos of people with a transparent background, and applied a script to randomly re-scale the figures and place them on photos of various locations. Through this, we could have photos with the person, as well as without the person. An example photo pair is shown below:

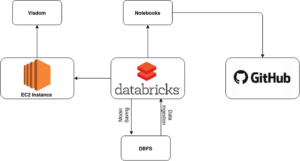
One cool thing about the pix2pix architecture is that it is sufficiently light to be run on an everyday laptop (granted, the laptop must have a GPU driver). However, the training is much faster if run in the cloud. Therefore, we uploaded the GAN architecture to Databricks.
One other noteworthy aspect of GANs is that defining the loss function is non-trivial. As opposed to computer vision classification tasks, ML forecasting, and basic NLP processes, quantifying when a GAN is doing a “good job” can be an especially tricky task (and, in fact, remains an active area of research). As such, the best approach is to carefully watch the output images being produced by the GAN during training, to be sure that things are going as expected. To do this, we used Visdom (https://github.com/facebookresearch/visdom), a tool which can visualize metrics and image output on a web browser in real time when tracking ML applications. Visdom was run on a micro EC2 instance, and a port was exposed via which information could be sent from Databricks.
With the addition of git integration, the final architecture was as follows:
With everything set up, we booted up the training routine, and (popcorn bucket in hand) watched the magic through Visdom.
At first, as expected, the GAN clearly has no idea what it is doing. It simply plays with the image hues, and makes images blurry. The below screen capture gives an example. The picture on the left is the input image, the centre picture is what the GAN generator has output, and the picture on the right is the true destination photo (which the Generator is not allowed to see until after it has output its attempt).
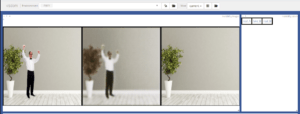
However, progress is relatively fast. After only a few epochs (each epoch taking around 10 seconds on Databricks, and each epoch comprising a pass through roughly 200 training photos) the GAN begins to consistently find the human figure in each photo.
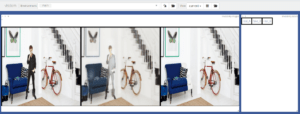
However, we see that the GAN is still not quite clear on what to do with the person. It simply makes their figure pale. Yet after a few hundred epochs, the GAN begins to understand what needs to be done, and learns to implement colours and features of the surroundings towards properly obscuring human figures. Here are some example after 200 epochs of training.







What about on Test Data?
It’s important to remember that training results are always more refined when compared to test results – that is, results obtained when applying the program to photos it has not yet seen. Our case is no exception. Here is what the Generator outputs when given a real photo it has not seen before (that is, a photo of a real person in a real place, as opposed to the script-generated stock photos shown above).

Looking at this, we see that we still have some work to do. But the results are still encouraging. First off, the GAN is able to locate the person within the image fairly consistently. Secondly, if we zoom in on one of the photos we can see that the GAN is still trying to use surrounding colours to edit out the figure:

Even if the test images are not perfectly handled, we shouldn’t be too hard on our GAN. That is to say, we need to keep in mind that the scope of this fun prototype was limited:
- The training data consisted of only 100 images, and 100 flipped images (data augmentation). A proper attempt would involve a few thousand images.
- The training was run for 200 epochs (100 normally, and 100 with learning rate decay). Again, a proper attempt would involve thousands.
- In the interest of time, hyperparameter tuning was not nearly as comprehensive as it could have been.
- The Generator architecture was also quite shallow (15 layers). There is no reason this couldn’t be pushed deeper.
Ultimately, and to put things in perspective, it’s still quite humbling that, in only an hour of training, a GAN with absolutely no idea what it’s supposed to be doing, nor any concept of what a ‘person’ is, can understand how to identify a figure and use the surroundings to edit away said figure. Another fun thought: as far as we know this is the first ever deployment of a full GAN on Databricks. Whoohoo!
Hopefully you’ve found this neat little application fun, and it has conjured up some fun childhood memories of the initial wonder of the Harry Potter Invisibility Cloak.

