
Part 1 – What is Meant by Computer Vision?
The First Sparks
One famous anecdote talks of how, in 1966, MIT Professor Marvin Minsky set up a summer project for some of his students.
They were asked to explore creating artificial vision systems which would ultimately recognize objects. By the end of the summer, the students were unable to meet the goals. However, this is not a reflection on the calibre of the students. Rather, it represents a first glimpse into the difficulties of the Computer Vision problem. Sometimes, when not familiar with the technologies, this can seem odd. Why is something so intuitive for us, but so difficult for a computer?

To be blunt: human eyes are complicated. Working out the intricacies of the photo-receptors, the nerves, and the manner in which vision manifests within the neurons of the brain has been a slow process spanning decades. And we are still nowhere near finished! Recent research is still uncovering fascinating aspects of our own brain-eye interplay, such as the fact that “vision” itself may happen more in the brain than in the eye (see Chariker et al. 2018 and Joglekar et al 2019).
All this to say, it should not surprise that primitive visual-cortex models from half a century ago gave underwhelming results when translated into computer architectures (also in their infancy).
Another issue is that rule-based “step-by-step” algorithms fall flat when asked to tackle computer vision problems. In the case of Object Recognition, the many angles, colours, and backgrounds in which an object can exist mean that any viable traditional (non ML) code will be monstrously long and inefficient.
Therefore, instead of bothering with the tedious “step-by-step” approach, the code must somehow be “let loose” to learn on its own.
Convolutions to the Rescue
The solution arrived in the form of an ingenious new neural network architecture called a “Convolutional Neural Network”, or CNN. Perhaps the most seminal moment in the birth of CNN was a 1989 paper by Yann LeCun in which he “taught” a network to recognize handwritten digits. This represented a very big step forward in Computer Vision, especially with respect to how the network could be repeatedly shown labelled images and gradually learn how to identify them. No rules need ever be defined.
Instead of one pixel per neuron, the neurons in a CNN are each fed a “grouping” of pixels from the image. This grouping is combined together mathematically (in general either the average or max of the grouping is taken) before being input into the neuron. The process of combining pixels is referred to as a “convolution”, hence the name.

Although groundbreaking, the first CNNs were still very restricted. On exceptionally straightforward tasks (such as digit recognition) they performed well, but they were unable to generalize to the plethora of situations humans encounter in our day-to-day lives.
Going Deeper
The next big leap forward would not come for another 23 years, in 2012.
At the time, ImageNet was the benchmark dataset for Computer Vision tasks. It contained 1000 classes of objects (a much more difficult challenge than 10 simple digits!). Large research bodies around the world converged each year to attempt to lower the error on the dataset – that is to say, reduce the number of falsely identified objects when a neural network is run on the images.
In 2012, a team led by Alex Krizhevsky designed an unusually deep neural network (although still quite shallow by today’s standards). Until that point, it had been assumed that such a deep neural network would be too computationally expensive to reasonably train, and that any gains in performance would be outweighed by this fact.
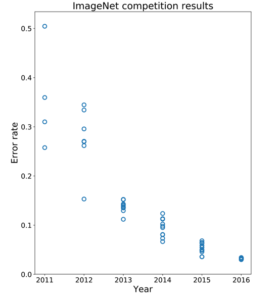
However, at the ImageNet competition in 2012, Alex’s neural network, named AlexNet, blew the competition out of the water. In the above graph of ImageNet performance with time, notice how one team lowered the error rate by around 10% in 2012. This was AlexNet, and its success in 2012 is part of a larger group of successes ushering in the beginning of the Deep Learning Revolution.
In subsequent years, the error rate was pushed even lower with further refinements.
Where we are now
We now find ourselves nearly a decade from the introduction of AlexNet. The decade has witnessed a breathtaking wave of AI innovation. Even if there are huge hurdles remaining to true human-level AI, tasks that were traditionally considered “Human-only territory” are being rapidly knocked into the “AI-possible” domain. As research pushes AI boundaries, state-of-the-art technologies are finding themselves applied in industry.
This is great news for Data Insights, as it means fascinating Computer Vision projects.
And with that brief into into the domain, let’s take a moment to enumerate a few examples!
Part 2 – Computer Vision in Data Insights
1 – Car Recognition
Data Insights was approached by a company seeking to identify car models. Specifically, the imagined AI system would be shown a photo, and would need to recognize the model of the car in said photo. To accomplish this task, a 150-layer CNN was trained in the cloud on over ten thousand photos of cars. Gradually it learned to recognize different car models, eventually achieving roughly 85% across 197 different models. Additionally powerful is that each prediction could be made in a fraction of a second. Much faster than possible for humans.
More information about the architecture is available here.
Link to Car Recognition video
2 – Handwriting Recognition
Another fascinating avenue is text extraction. Specifically, we have been approached by a number of companies looking to create programs to parse files and extract text. In the simplest case, these are forms containing computer generated text. A Computer Vision technology named Optical Character Recogntion (OCR) can be used to parse documents and extract text.
Somewhat more challenging, but now possible with state-of-the-art CNN, are handwritten documents. As handwriting comes in a huge variety of shapes and styles, research groups have only recently been able to reliably extract handwritten text. And cloud solutions have also started to appear (eg Azure OCR).
One final “cherry-on-top” extension is the addition of Natural Language Processing (NLP). With NLP, it is possible to apply language logic to extracted text to “fix-up” typos and grammatical errors. For example, if the OCR has extracted “the fool was super tasty!”, NLP can infer that it would be more logical for the sentence to have been written “the food was super tasty!”. Through this, combining NLP as an additional step leads to a fantastic boost in extraction accuracy.

An example architecture for handwritten text extraction. The final layer (LSTM) is a popular NLP architecture which can apply language logic to text data.
Once the handwritten documents have been digitized and retouched via NLP, additional ML layers can be applied for a whole range of use cases. For example, documents can be automatically sorted into different document types via clustering algorithms. Or anomaly detection can be applied to identify suspicious oddities within the documents (perhaps, for example, in the case of an audit).
3 – GANs
One fascinating Computer Vision technology to have emerged in the past few years is Generative Adversarial Networks (GANs). These networks work exceptionally well when photos need to be manipulated in a manner more complicated than what traditional CNNs allow. For example, colourizing old black and white photos, automatically blurring faces, or turning satellite photos into maps. GANs perform excellently on these more “complicated non-traditional” Computer Vision Tasks.
Data Insights wanted to have a demo GAN to explore this new technology. We deployed a GAN on Databricks, and linked it with GitHub such that changes would be registered in a remote repository. Additionally, Databricks was connected to an Amazon EC2 instance, which would allow training to be visualized using the Facebook application Visdom. Below you can see what it looks like within Visdom when the application is training. The images on the top show what the GAN is “seeing”, and the orange curve show how well the GAN is “learning”.
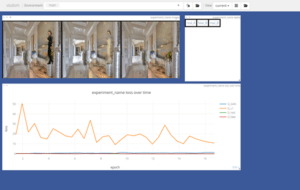
We taught the GAN to identify people within photos, and colour them out of the photos. This could be used for automatic data anonymization.
Below are some of the results when applied to real photos which the GAN had not seen before:

The GAN is able to consistently identify where the person is within the photo and blur them.
4 – Pill Defect Detection
A pharmaceutical company approached Data Insights to help with detecting defects within batches of medication. Computer Vision is now exceptionally good at such tasks. One advantage is that modern AI systems are not only much faster than humans, but they are not susceptible to fatigue and distractions.

An added bonus is that such tasks can incorporate something known as Variational AutoEncoders (VAE). This technology allows Computer Vision systems to automatically encode the features of what an object “should look like”. Once this is done (using thousands of pills, for example) the AI system can notice subtle variations which stand out against what has been learned as “normal”. Through this, we do not need to explicitly and tediously label images as “normal” and “defective” – the AI system can do that on its own.
Do you have any interesting problems which Computer Vision may be able to solve?
Data Insights is ready to help you get started!

