
Introduction
Azure is a cloud computing platform with a wide range of services that provide solutions for various business applications. This includes database hosting, remote storage, ETL services, etc. In this blog we take a comprehensive look at Azure Data Factory in combination with Databricks.
Azure Data Factory is a useful tool for performing ETL processes, and as such performs the task of moving data from various sources into a data lake or data warehouse. It helps us to easily orchestrate the data movement and work with the data that is then further used by end users/systems such as BI tools. It also allows us to create data-driven workflows called data pipelines. Thanks to the visual tools, it is very easy for us to construct ETL processes.
In the following article, we will go through all the steps to create an ETL pipeline with Data Factory using Databricks Python Activity.
Prerequisites
1. The Azure Data Factory resource should be created and configured using Github or Azure DevOps in the Azure portal.
2. A Databricks workspace should be configured in the Azure subscription, with a cluster and a file containing the transformation logic.
3. Azure Data Lake Storage account is configured in Azure Subscription.
Perform a data ingest using the Copy Data tool to copy raw data
1. Navigate to the Azure Data Factory home page in your browser and create a new pipeline.

2. Next, under Activities → Move and Transform, select the Copy Data Activity as shown in the figure below and drag it to the workspace.

3. Create a linked service to connect to the source dataset. In this step, we need to fill in the required details to connect to the source dataset.

Azure supports connection to many external data sources along with native Azure data sources.

4. Similarly, we create a linked service to connect to the Sink dataset. In our case, it should be Azure Data Lake Storage so we can use it later for transformation with Databricks. We should have already created a container in ADLS to store the Sink dataset which will be used in this step.
5. We can test the connections to make sure they work by selecting a record in the left navigation bar and then using the Test Connection button, as shown in the figure.

Once this is complete, we can run this part in debug mode to be sure that the data copy tool is working. We should check the sink container in ADLS to see if the data copy tool worked correctly and if we have new data after running it. In the next steps, we will look at how we can transform this data using the Databricks Python Activity.
Perform a transformation job using Databricks Python Activity
1. Once the data copy activity is implemented, we can add a Databricks Python Activity job that will transform the data ingested by the Copy Data tool job. Databricks provides a unified, open platform that enables powerful ETL analytics and machine learning. Therefore, we are taking the opportunity here to incorporate Databricks activities into the Data Factory pipeline.

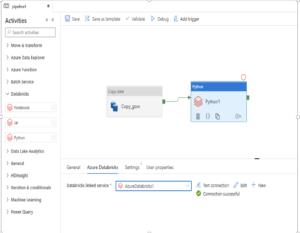
The blocks can be connected by dragging an arrow from the green square to the right of the Copy data block to the Python transform job, which indicates the execution path of the end-to-end pipeline.

2. Then we need to configure the Databricks Python Activity. First, we need to connect this Activity to a Databricks linked service. To do this, we need to create a Databricks linked service or use an existing one. The linked service will help us connect to the Databricks workspace and run the Python Activity by deploying a configured Databricks cluster. The linked service should be tested for a successful connection. Important parameters for connecting to the Databricks workspace are the workspace name, workspace URL, authentication type, and other configurations of the cluster such as node type and autoscaling.
3. The next step is to specify the DBFS path of the Python file to be executed. This would be the main file that will be executed by this Activity. This file must contain the transformation logic to transform the ingested data and write the transformed data back to Azure Data Lake Storage.

4. The next step is to specify the optional parameters and libraries if required. Different library types can be used, e.g. pypi, python wheels, etc. After specifying the library type, we also need to specify the DBFS URI of the python library or the package name of pypi. These are dependent libraries required by the main python file as shown in the figure below.

5. Once these settings are determined. Open the Databricks workspace and check the DBFS paths of the main Python file and the Python wheel file set in the data factory as shown in the figure below.

Our end-to-end pipeline is now complete. We need to validate, test, and publish our pipeline. The pipeline can be validated using the validate button. Once validation is complete, the pipeline can be run in debug mode to test the results. Once we have the transformed data in ADLS, we can verify the correctness of the transformed data.
After testing, the pipeline can be published using the publish command. The publish command merges the current branch with the publish branch. All production-ready workloads should be merged into the publish branch for regular deployment.
The last step is to add a trigger that sets the execution frequency of the pipeline. Here we need to specify the start date, the time zone, and the repetition of the job.
Conclusion
We have covered all the steps to successfully create an ETL pipeline using Databricks orchestrated by Azure Data Factory. As shown above, managing the pipeline becomes quite easy using Data Factory’s GUI tools. Monitoring the pipeline is also quite easy by assigning these pipelines to Azure Monitor. With the help of Azure Monitor, alerts can be easily created to inform us immediately about any error in the pipeline execution.
The ability to include Databricks allows us to write complex transformation code in Spark, which is not possible with native Data Factory tools. Therefore, a combination of Data Factory and Databricks is perfect for creating complex ETL pipelines in Azure.

